In two earlier posts I detailed the simple methods I use for file type identification and the issues that arise from them. Here I’m going to look at a few more resources for file type identification, including some applications and websites that host useful file type information. The first part will just discuss places to look, the second will be a mild analysis of some software provided by the National Archives of the United States. I’m using file type and format interchangeably from now on to make it less boring to write.
File Formats and Internets
Aside from searching for a file format on the Google or Wikipedia, both of which meet with sometimes limited success, there are some good places to check. One is Jason Scott’s effort at the Just Solve the Problem Project, in which he got Archive Team members and anyone on the Internet to rabidly organize a file formats wiki. The site has a rather large number of file formats, though your mileage may vary with more obscure proprietary types. At least if you find something new you can add it to the listings. I like this site since it tries to include many formats that might not be floating around the Internet, like internal Playstation development files and other internal formats. There’s also a great collection of links on the project proposal wiki with tons of other file format resources.
Another listing of file formats, which is much less complete but still potentially useful is the UK National Archives file format database PRONOM. The UK National Archives actually uses this database for file identification in the applications I’m going to mention below. It’s a little hard to parse at first and the UI needs some work, but there is some good information in there.
Applications
I’m going to look at three applications in brief, just to give a flavor of what’s available for free and immediately. There are tons of expensive computational forensics tools that you could use for this analysis. In fact, when I was working on the Stanford collections I had access to some, they were quite nice and around $5000 a license. FTK Tool Kit is an example of this type of forensic software and its purpose is mostly for document discovery in court cases. As such it is not interested in weird file format identification. It can, however, search a hard drive for any data that might be an image of a human. Not going any farther with that comment.
Back to the free, non-spook world, I’m going to look at JHOVE, JHOVE2 and DROID; three programs designed for digital repositories and libraries. Starting with JHOVE, or the JSTOR/Harvard Object Validation Environment, I’m going to outline an attempt to use the software for identification of file types. As is apparent from the name, JHOVE was an effort to provide document validation for university digital repositories. Validating a file format is very important since it ensures that it follow an accepted standard specification and thus will probably be readable in the future. Sadly, for my current purposes, this software is not very useful. JHOVE only validates and identifies files related to digitization of print material, which is the basis for most digital collections and certainly not related in the slightest to arbitrary software archives. JHOVE will tell you is a certain PDF is version 1 or 1.7, but it treats most non-text and non-image formats as black-boxed bitstreams. It is also not really supported at this point, so while it’s probably possible to modify its internals, I really don’t have the time.


JHOVE interpreting an unknown file type
JHOVE2 is the result of a two-year grant to try and improve the scope and functionality of the original JHOVE software, however it seems to be only partly finished and labor intensive. JHOVE2 provides for a larger range of file type identification but still only deals with the major print and image based formats of the original JHOVE. Additionally, JHOVE2 does not have an graphical user interface, so all analysis must be done either through the command line or by writing your own rules for the system and designing custom output. I could see the latter being great if you had a full-time staff member managing it, but the 40 pages installation and usage manual is too intense for my current needs and time constraints. JHOVE2 also appears to have just run out of development time. Running the default configuration on a single text file gives me a 300+ line XML document that I can barely parse. Luckily, JHOVE2 uses access to the DROID application as a backend file format search. A fact that lead me and will lead this blog post to brighter pastures.

Partial JHOVE2 Output for the Apache License
DROID or, Digital Record Object IDentification, is a Java program developed by the UK National Archives for file format identification. It accesses the online PRONOM database mentioned above and will try to identify the file types in a given folder. Since the PRONOM database does have a decent amount of common files, DROID was able to identify some common Actionscript and Flash development files. Although some of the more confusing files through it off, specifically all the difficult ones I mentioned in this post, it also managed to find file extensions that I had missed the first time around. So that’s a total win! DROID has a nice reporting feature that will enumerate the different file extensions it found and give their number. While I would have liked full path information, at least this can give someone a basic overview of the proprietary or potentially confusing file formats immediately. Thereby allowing one to narrow later searches to just those files for identification.
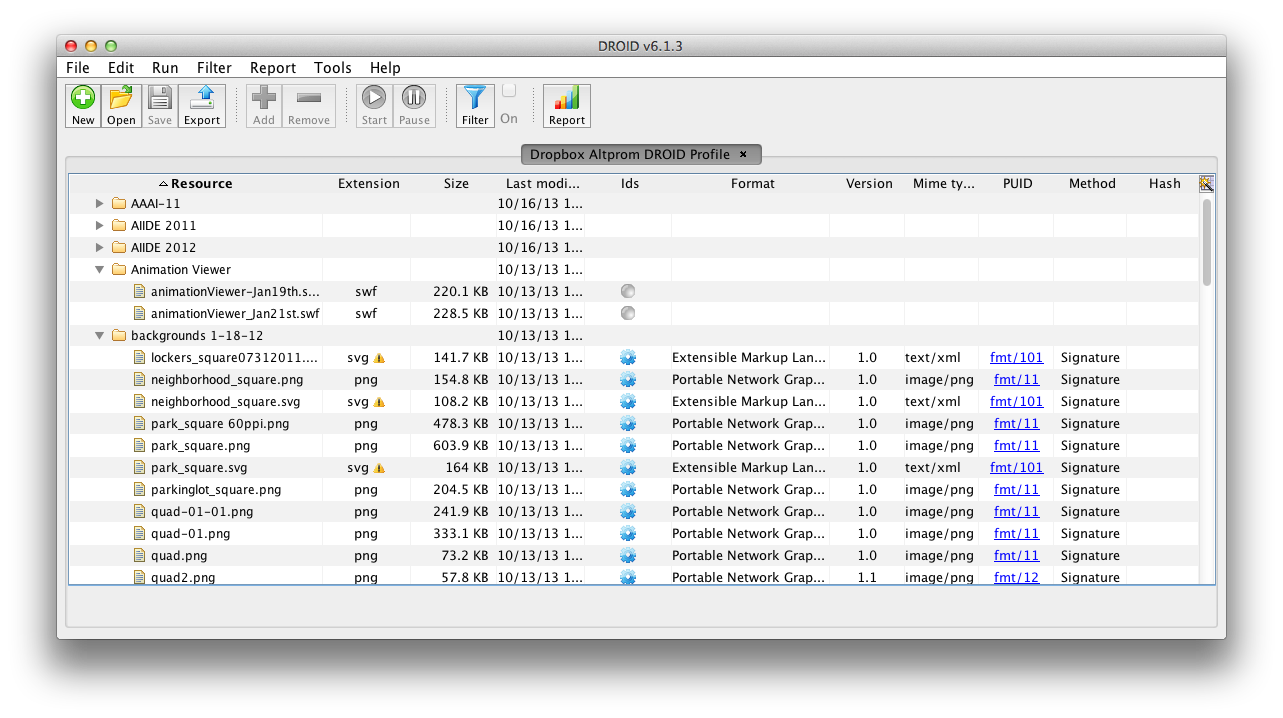
DROID UI
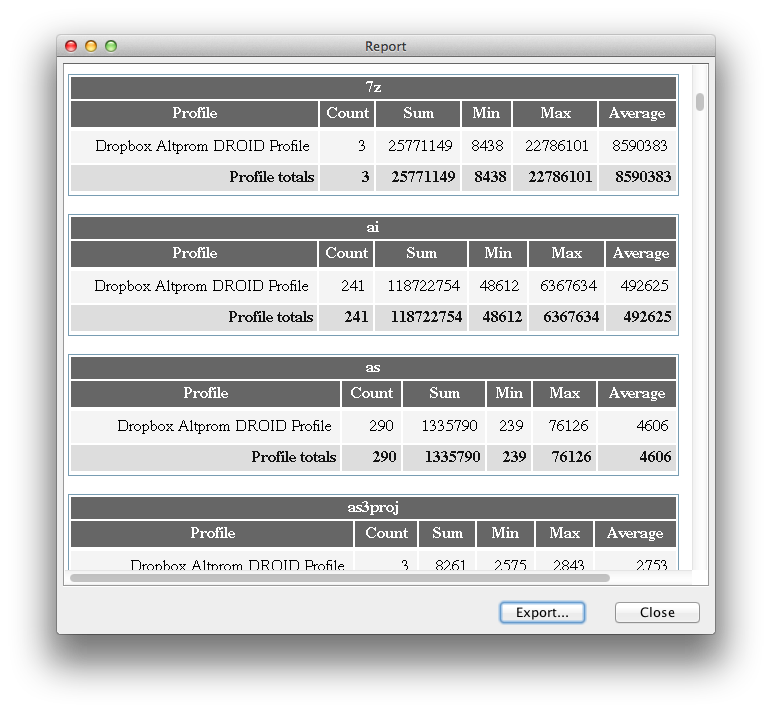
DROID Generated Report
Okay, so that’s a could of the programs I’ve messed with to identify files. Next time join me for some basic email analysis thanks to the good folks at the Stanford MUSE Project.





